 Polski
Polski  English
English Symulacje Monte Carlo, część 1

Prognozy to zgadywanie przyszłości. Symulacje Monte Carlo pozwalają określić prawdopodobieństwo trafności przewidywań.
Niezależnie od tego, czy Zespół realizuje tradycyjne projekty, rozwija produkty w sposób zwinny (np. z użyciem Scruma) albo używa Kanbana do zrządzania przepływem w procesie pracy ciągłej, zmagać się będzie z takimi oto pytaniami:
- Co zostanie zrealizowane do określonej daty?
- Kiedy zakończona zostanie praca nad konkretną rzeczą?
- Ile czasu i środków potrzeba, by wykonać określony zakres prac?
Odpowiedzi na te i podobne pytania pozwalają podejmować decyzje strategiczne i taktyczne, a także kontrolować ryzyko inwestycyjne. Pośrednio pozwalają też ustalić, jaki Zespół lub Zespoły i na jak długo będą potrzebne, by wytyczony cel biznesowy osiągnąć.
Z racji tego, że pytania dotyczą przyszłości, każda z odpowiedzi jest w istocie oszacowaniem lub ewentualnie prognozą, czyli oszacowaniem wraz z określeniem poziomu niepewności, z jakim zostało ono sporządzone. Jeszcze do różnicy pomiędzy oszacowaniami a prognozami wrócę w dalszej części artykułu.
Jak takie oszacowania i prognozy są sporządzane? Dobór narzędzi zależy od sposobu działania Zespołów i metod, jakimi się one posługują. Można jednak powiedzieć, że polega to na nałożeniu informacji o tempie prac Zespołu lub jego możliwościach wytwórczych na listę rzeczy do zrobienia.
W ten właśnie sposób wykorzystywana jest w wielu Zespołach informacja o prędkości (ang. velocity) albo przepustowości (ang. throughput) osiąganej w kolejnych przedziałach czasu (np. w tygodniu czy iteracji). Używając średniej wartości którejś z tych miar za wybrany historyczny okres, da się oszacować, ile pracy zostanie ukończone w podobnym okresie w przyszłości. Zwracam uwagę: to oszacowanie, bo nie da się określić poziomu pewności, z jakim zostało sporządzone.
Można też wyliczyć wartość minimalną i maksymalną prędkości lub przepustowości i sporządzić na tej podstawie dwa oszacowania: pesymistyczne i optymistyczne. Użyte razem, tworzą jedną prognozę, a skala rozbieżności pomiędzy obydwoma oszacowaniami podpowiada, jaki jest poziom jej niepewności.
Jeśli wariant pesymistyczny wskazuje, że być może w tydzień uda się zrobić zaledwie 10 rzeczy, a optymistyczny, że może ich być nawet 50, to prognoza jest bardzo nieprecyzyjna i niepewna. Zdecydowanie dokładniejszą jest taka, która zapowiada, że być może uda się zrobić od 15 do 20 rzeczy.
Prawdopodobieństwo sprawdzenia się prognozy
Dla tego rodzaju prognoz w zasadzie nie da się określić prawdopodobieństwa, które się z nimi wiąże. Przyjrzyjmy się przykładowej prognozie:
W ciągu kolejnych dwóch tygodni Zespół zrealizuje od 3 do 11 rzeczy.
Prognoza ta sporządzona została na podstawie danych z 2023 o przepustowości pewnego Zespołu, który pracuje w dwutygodniowych iteracjach.
W jakim stopniu prawdopodobne jest, że to będą tylko 3 rzeczy? A w jakim, że aż 11? Nie da się tego łatwo wyliczyć, o ile w ogóle jest to możliwe. Funkcja matematyczna, która opisuje przebieg prac w kolejnych dwóch tygodniach, nie jest nam znana, bo zbyt wiele czynników może wpłynąć na działania Zespołu. Tym samym nie da się również obliczyć prawdopodobieństwa uzyskania konkretnego efektu zadziałania tej nieznanej funkcji.
Czy jest przynajmniej możliwe ustalenie, jaki scenariusz jest najbardziej prawdopodobny? Wiele osób jest przekonanych, że wiąże się to z wykorzystaniem do sporządzenia prognozy wartości średniej prędkości lub przepustowości. Dla przykładowego Zespołu wyglądałaby ona tak:
W ciągu kolejnych dwóch tygodni Zespół zrealizuje od 3 do 11 rzeczy, a najprawdopodobniej 7.
Wartość 7 jest całkowitą liczbą najbliższą średniej przepustowości, jaką Zespół uzyskiwał w 2023 – wyniosła ona dokładnie 7.1 rzeczy na iterację.
Nadal oczywiście nie wiadomo, jakie prawdopodobieństwo wiąże się z każdym z tych trzech oszacowań, a do tego pojawia się przekonanie, że na pewno uda się zrobić przynajmniej te 3 elementy. Inaczej mówiąc, odbiorcy tej informacji zaczynają traktować wariant pesymistyczny prognozy jako skrajny, a zatem nieprawdopodobny i spodziewają się, że sprawy potoczą się zapewne lepiej.
Co znamienne, podobnie skrajnego wariantu optymistycznego nikt nie traktuje konsekwentnie jako równie nieprawdopodobny – wszyscy mają nadzieję, że jednak uda się zrobić 11 rzeczy, a może nawet i więcej.
Tymczasem prawdopodobieństwo, z jakim trzy scenariusze zawarte w prognozie mogą się ziścić, wygląda w przykładowym Zespole następująco (skąd je znam, wyjaśnię później):
- Prawdopodobieństwo ukończenia 3 rzeczy wynosi 8.46%.
- Prawdopodobieństwo ukończenia 7 rzeczy wynosi 14.06%.
- Prawdopodobieństwo ukończenia 11 rzeczy wynosi 2.37%.
Jak widać, wariant „najbardziej prawdopodobny”, czyli związany ze średnią przepustowością, wiąże się z prawdopodobieństwem zaledwie nieco ponad czternastoprocentowym i nie jest ono o rząd wielkości wyższe od prawdopodobieństwa wariantów pesymistycznego i optymistycznego.
Przy czym cudzysłów, jakiego używam, pisząc o wariancie „najbardziej prawdopodobnym”, nie jest przypadkowy. Oto bowiem pełna prognoza możliwych wartości przepustowości w przyszłej iteracji omawianego Zespołu:
| Przepustowość | Prawdopodobieństwo |
|---|---|
| 0 | 0.26% |
| 1 | 1.47% |
| 2 | 4.28% |
| 3 | 8.46% |
| 4 | 12.79% |
| 5 | 15.71% |
| 6 | 15.99% |
| 7 | 14.06% |
| 8 | 10.84% |
| 9 | 7.27% |
| 10 | 4.44% |
| 11 | 2.37% |
| 12 | 1.19% |
| 13 | 0.53% |
| 14 | 0.22% |
| 15 | 0.08% |
| 16 | 0.03% |
| 17 | 0.01% |
Prawdopodobieństwo uzyskania średniej przepustowości 7 rzeczy na iterację jest niższe niż prawdopodobieństwo ukończenia 6, a nawet 5 rzeczy. Uzyskanie średniej przepustowości nie jest więc wcale najpewniejszym scenariuszem.
Wizualna reprezentacja tych samych danych na wykresie przypomina (co zapewne nikogo nie zaskoczy) rozkład normalny:
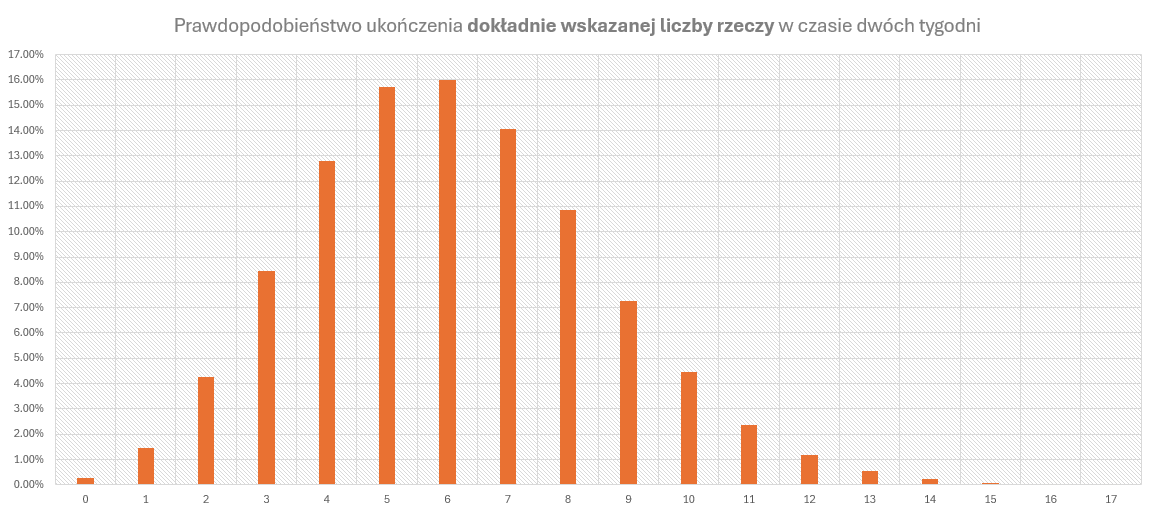
Skomplikujmy ten obrazek nieco bardziej
Czy prawdopodobieństwo ukończenia dokładnie 3 rzeczy w dwa tygodnie jest takie samo jak prawdopodobieństwo ukończenia co najmniej 3 rzeczy w tym samym czasie? Niektórzy powiedzą, że tak. Inni powiedzą, że jest niższe. A w istocie jest ono co najmniej takie samo lub wyższe, nierzadko zaś dużo wyższe. Dlaczego?
Wróćmy raz jeszcze do przykładowego Zespołu, którego danymi posługuję się w ramach artykułu. W tabeli zaprezentowanej powyżej możemy sprawdzić, jaka jest szansa na uzyskanie konkretnej przepustowości i widać, że jest różna w poszczególnych wierszach, ale nigdzie nie przekracza 16%.
Natomiast każdy scenariusz ukończenia przynajmniej jakiejś liczby rzeczy w iteracji jest z definicji szerszy niż scenariusz ukończenia dokładnie określonej ich liczby. Przykładowo, ukończenie dokładnie 10 rzeczy w dwa tygodnie jest związane z prawdopodobieństwem 4.44%. Natomiast prawdopodobieństwo ukończenia co najmniej 10 rzeczy to suma prawdopodobieństwa, że tych rzeczy będzie 10 (4.44%), albo 11 (2/37%), albo 12 (1.19%) itd.
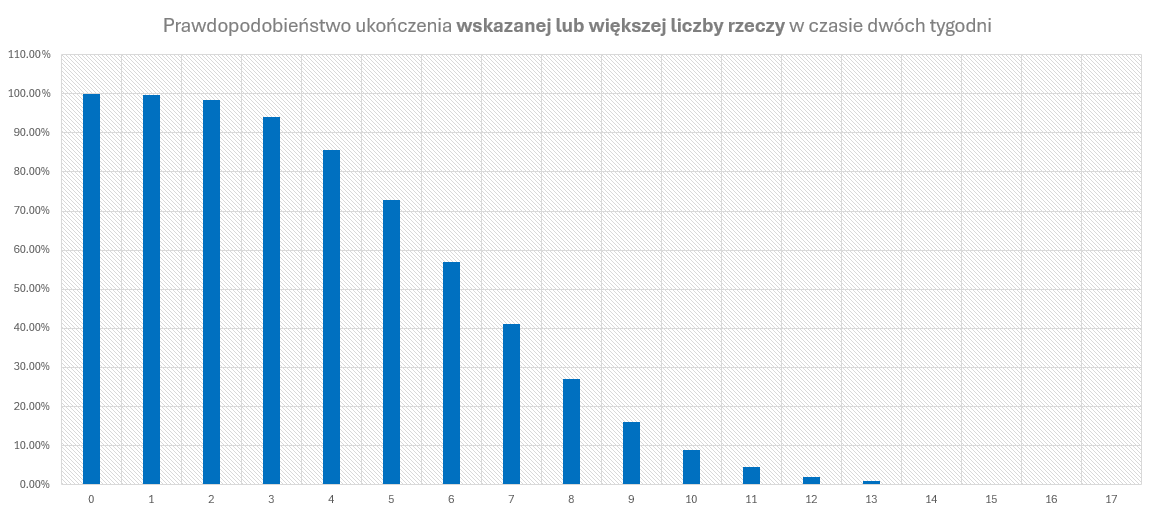
Kompletna prognoza określającą prawdopodobieństwo ukończenia przynajmniej określonej liczby rzeczy dla przykładowego Zespołu w ciągu kolejnej iteracji wygląda zatem następująco:
| Minimalna przepustowość | Prawdopodobieństwo |
|---|---|
| 0 | 100.00% |
| 1 | 99.74% |
| 2 | 98.27% |
| 3 | 93.99% |
| 4 | 85.53% |
| 5 | 72.74% |
| 6 | 57.02% |
| 7 | 41.04% |
| 8 | 26.98% |
| 9 | 16.14% |
| 10 | 8.87% |
| 11 | 4.43% |
| 12 | 2.05% |
| 13 | 0.86% |
| 14 | 0.33% |
| 15 | 0.12% |
| 16 | 0.04% |
| 17 | 0.01% |
Również i te dane da się przedstawić graficznie na wykresie, na którym widać wyraźnie, jak spada prawdopodobieństwo, gdy rośnie przewidywana minimalna liczba ukończonych rzeczy:
Jak wyliczyć te prawdopodobieństwa?
Cóż, jak już wspominałem, nie da się ich po prostu wyliczyć w jakiś magiczny sposób z danych, które jest w stanie zebrać Zespół. Może on monitorować swoją przepustowość (tak robił Zespół, którego przykładem się posługuję), może gromadzić mnóstwo innych informacji, ale nie będzie w stanie zrobić jednego: zapisać matematycznej formuły, na podstawie której wyliczy prawdopodobieństwo jakiegokolwiek zdarzenia.
Skąd więc biorą się dane, które prezentuję? Są one efektem przeprowadzenia symulacji Monte Carlo, która wykorzystuje historyczne dane do wygenerowania różnych scenariuszy przebiegu przyszłych iteracji. Po przeprowadzeniu dużej liczby takich symulacji (ja zrobiłem ich okrągły milion), można dokonać analizy statystycznej uzyskanych wyników i wyliczyć prawdopodobieństwo zdarzenia, które nas interesuje.
Przy czym nie jest to żadna zaawansowana matematyka. Przykładowo, skoro 44411 symulacji z miliona kończyło się zrealizowaniem 10 rzeczy w trakcie iteracji, to znaczy, że prawdopodobieństwo uzyskania przez Zespół takiej przepustowości wynosi 44411 na milion, czyli 4.4411%.
Prognozy mimo braku wycen
Uważny czytelnik artykułu zwrócił pewnie uwagę, że nigdzie nie wspominam o wycenach rzeczy, które oczekują na realizację przez Zespół. Zupełnie tak, jakby wyceny te były zbędne do sporządzania prognoz potencjalnych dat ukończenia. I faktycznie, są one zbędne, bo da się prognozować niezależnie od tego, czy Zespół dokonuje wycen i w jakiej formie są one sporządzane.
Oczywiście, jeśli podstawą do prognozowania jest velocity, czyli prędkość Zespołu, to bez stosownych wycen się nie obejdzie, a co więcej muszą one mieć wartości numeryczne. Prędkość w jakimś okresie jest bowiem wyliczana jako suma oszacowań rzeczy, które w tym czasie zostały zrealizowane.
Natomiast jeśli posłużymy się przepustowością, wyceny nie mają znaczenia. Throughput w jakimś okresie to po prostu liczba rzeczy, które w tym czasie zostały zrealizowane.
Jak przeprowadzić symulację Monte Carlo?
O tym piszę w kolejnej części artykułu. Oczywiście jest to podpowiedź jednego ze sposobów, jak można symulację wykonać – wszystko bowiem zależy od danych, jakimi dysponujemy i oczekiwanej dokładności prognozy, którą chcemy sporządzić. A także, nie ma co ukrywać, od umiejętności technicznych (jeśli symulację robimy sami), albo możliwości narzędzi, jakimi dysponujemy (jeśli korzystamy z gotowych rozwiązań).
O autorze

Rafał Markowicz
Professional Scrum Trainer
Developer, doświadczony Scrum Master i Professional Scrum Trainer akredytowany przez Scrum.org (PST), w branży IT od 2001.
Developer, doświadczony Scrum Master i Professional Scrum Trainer akredytowany przez Scrum.org (PST), w branży IT od 2001.